NumPy, SciPy, Pandas 相关性计算及可视化 |
您所在的位置:网站首页 › python kendall相关系数 › NumPy, SciPy, Pandas 相关性计算及可视化 |
NumPy, SciPy, Pandas 相关性计算及可视化
|
相关性系数 数量化了一个数据集的变量或特征之间的关联。这些统计数据对科学和技术具有高度的重要性,Python有很好的工具,诸如SciPy、NumPy和Pandas,都可以用来计算,并且它们的相关方法是快速、全面和有据可查的。 什么是皮尔逊、斯佩尔曼和肯德尔相关性系数 如何使用SciPy、NumPy和Pandas的相关性函数 如何用Matplotlib实现数据、回归线和相关矩阵的可视化 相关性统计学和数据科学通常关注数据集的两个或多个变量(或特征)之间的关系。数据集中的每一个数据点都是一个观察值,而特征是这些观察值的属性或特性。 我们所处理的每一个数据集都使用了变量和观测值。例如: 篮球运动员的身高与投篮命中率有什么关系 员工工作经验与工资之间是否有关系 不同国家的人口密度和国内生产总值之间存在什么数学上的依赖关系? 在上面的例子中,身高、投篮命中率、工作年限、工资、人口密度和国内生产总值是特征或变量。与每个球员、雇员和每个国家有关的数据是观察值。 当数据以表的形式表示时,该表的行通常是观察值,而列是特征。看一下这个雇员表。 姓名经验/m工资/$才哥30120,000小明21105,000一哥1990,000云朵1082,000在这个表中,每一行都代表一个观察值,或者说是一个雇员的数据。每一列显示所有员工的一个属性或特征(姓名、经验或工资)。 如果分析一个数据集的任何两个特征,会发现这两个特征之间存在某种类型的相关性。 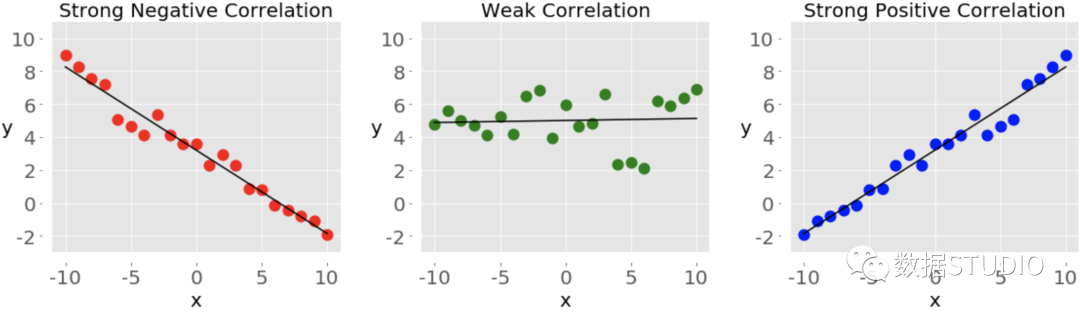
这些图中的每一个都显示了三种不同形式的相关关系中的一种。 负相关(红点)。 在左边的图中,y值随着x值的增加而趋于减少。这显示了强烈的负相关,当一个特征的大值对应于另一个特征的小值时,就会出现这种情况,反之亦然。 弱或无相关性(绿点)。 中间的图显示没有明显的趋势。这是弱相关的一种形式,当两个特征之间的关联不明显或几乎观察不到时,就会出现这种情况。 正相关(蓝点)。 在右边的图中,y值随着x值的增加而增加。这说明了强烈的正相关,当一个特征的大值对应于另一个特征的大值时,就会出现这种情况,反之亦然。 下图代表了上述雇员表中的数据。 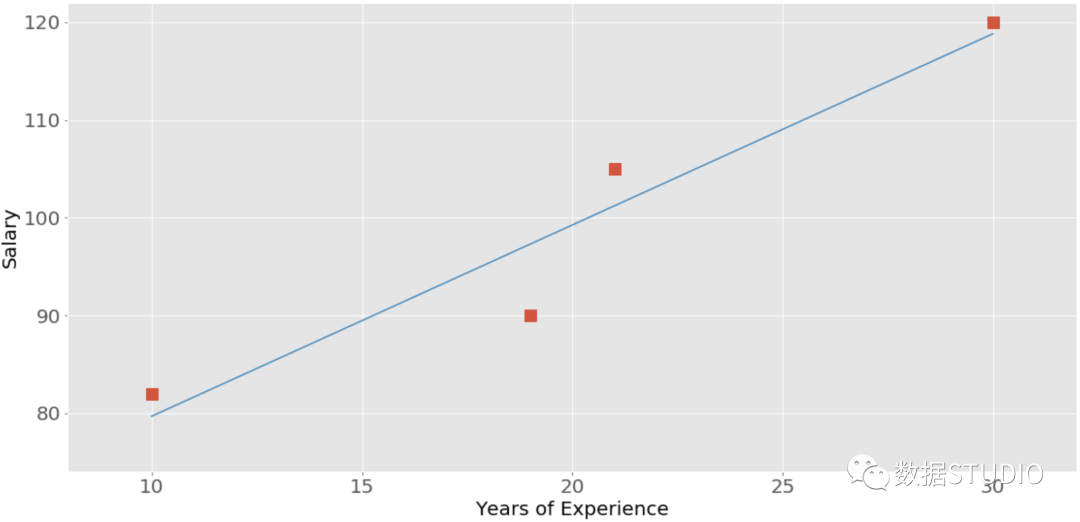
经验和工资之间的相关性是正的,因为较高的经验对应着较高的工资,反之亦然。 注意: 当分析相关关系时,记住相关关系并不表示因果关系。它量化了一个数据集的特征之间的关系强度。有时,关联是由几个相关特征的共同因素造成的。 相关性与其他统计量如平均数、标准差、方差和协方差有着紧密的联系。有几种统计数据可以用来量化相关关系。这里我们学习三种相关系数。 Pearson’s r 皮尔逊相关系数 Spearman’s rho 斯皮尔曼系数 Kendall’s tau 肯德尔系数 皮尔逊系数衡量线性相关[1],而斯皮尔曼和肯德尔系数则比较数据的等级[2]。有几个NumPy、SciPy和Pandas的相关函数和方法,我们可以用来计算这些系数。还可以使用Matplotlib来方便地可视化结果。 NumPy计算相关性NumPy有很多统计函数[3],包括np.corrcoef()[4],可以返回皮尔逊相关系数的矩阵。可以从导入NumPy并定义两个NumPy数组。这些是x和y的ndarray类的实例。 >>> import numpy as np >>> x = np.arange(10, 20) >>> x array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19]) >>> y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> y array([ 2, 1, 4, 5, 8, 12, 18, 25, 96, 48])在这里使用np.range()创建一个10(包括)和20(不包括)之间的整数数组x。然后使用np.array()创建第二个包含任意整数的数组y。 一旦我们有两个相同长度的数组,就可以以两个数组为参数调用np.corrcoef()。 >>> r = np.corrcoef(x, y) >>> r array([[1. , 0.75864029], [0.75864029, 1. ]]) >>> r[0, 1] 0.7586402890911867 >>> r[1, 0] 0.7586402890911869corrcoef() 返回相关矩阵,它是一个包含相关系数的二维数组。下面是我们刚刚创建的相关矩阵的简化版本。 x y x 1.00 0.76 y 0.76 1.00相关矩阵的主对角线上的数值(左上和右下)都等于1,左上的数值对应于x和x的相关系数,而右下的数值是y和y的相关系数,它们总是等于1。 然而,我们通常需要的是相关矩阵的左下方和右上方的值。这些值是相等的,都代表x和y的皮尔逊相关系数。这里大约是0.76。 该图显示了上述例子的数据点和相关系数。 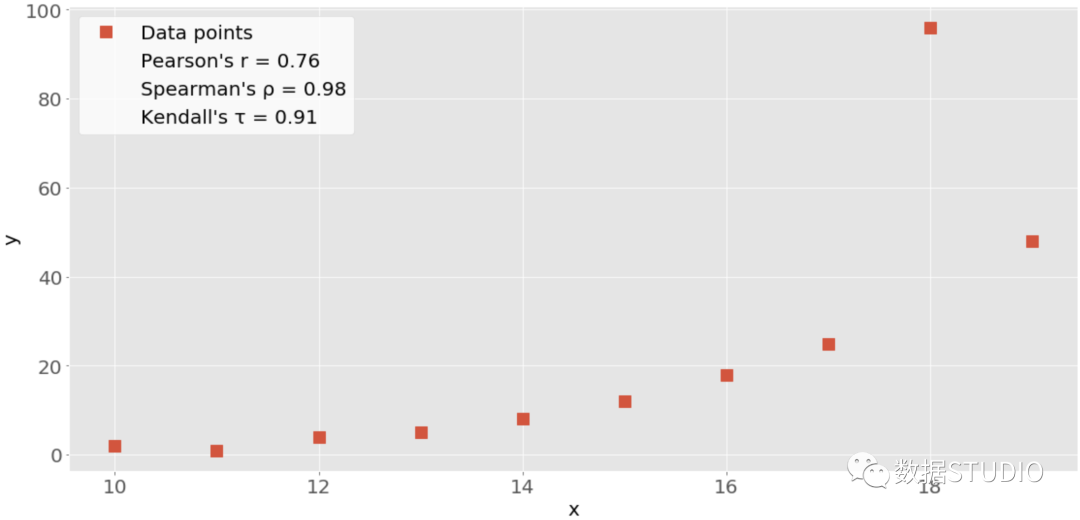
红色的方块是数据点,该图还显示了三个相关系数的值。 SciPy 计算相关性SciPy也有许多统计函数,包含在scipy.stats[5]中,可以使用以下方法来计算之前的三个相关系数。 pearsonr() spearmanr() kendalltau() 下面是我们如何在Python中使用这些函数。 >>> import numpy as np >>> import scipy.stats >>> x = np.arange(10, 20) >>> y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> scipy.stats.pearsonr(x, y) # Pearson's r (0.7586402890911869, 0.010964341301680832) >>> scipy.stats.spearmanr(x, y) # Spearman's rho SpearmanrResult(correlation=0.9757575757575757, pvalue=1.4675461874042197e-06) >>> scipy.stats.kendalltau(x, y) # Kendall's tau KendalltauResult(correlation=0.911111111111111, pvalue=2.9761904761904762e-05)注意,这些函数返回包含两个值的对象: 相关系数 P值 在统计方法中,当测试一个假设时,会使用P值。p值是一个重要的衡量标准。可以提取p值和相关系数及其指数。 >>> scipy.stats.pearsonr(x, y)[0] # Pearson's r 0.7586402890911869 >>> scipy.stats.spearmanr(x, y)[0] # Spearman's rho 0.9757575757575757 >>> scipy.stats.kendalltau(x, y)[0] # Kendall's tau 0.911111111111111我们也可以对 Spearman 和 Kendall 系数使用点符号。 >>> scipy.stats.spearmanr(x, y).correlation # Spearman's rho 0.9757575757575757 >>> scipy.stats.kendalltau(x, y).correlation # Kendall's tau 0.911111111111111点符号比较长,但它也更易读,更容易说明问题。 如果我们想同时得到皮尔逊相关系数和p值,那么可以把返回值解包。 >>> r, p = scipy.stats.pearsonr(x, y) >>> r 0.7586402890911869 >>> p 0.010964341301680829这种方法利用了Python的解包,以及pearsonr()返回一个包含这两个统计量的元组的事实。我们也可以在spearmanr()和kendalltau()中使用这种技术,后面我们会看到。 Pandas计算相关性在某些情况下,Pandas比NumPy和SciPy更便于计算统计数据,它为Series和DataFrame实例提供统计方法。例如,给定两个项目数量相同的系列对象,可以在其中一个对象上调用.corr()[6] 方法,而另一个对象作为第一参数。 >>> import pandas as pd >>> x = pd.Series(range(10, 20)) >>> y = pd.Series([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> y >>> x.corr(y) # Pearson's r 0.7586402890911867 >>> y.corr(x) 0.7586402890911869 >>> x.corr(y, method='spearman') # Spearman's rho 0.9757575757575757 >>> x.corr(y, method='kendall') # Kendall's tau 0.911111111111111这里使用 .corr() 来计算所有三个相关系数,用参数方法定义所需的统计量: 'pearson' 'spearman' 'kendall' 一个可调用的程序 可调用程序可以是任何函数、方法或带有`.__call__()`[7]的对象,接受两个一维数组并返回一个浮点数。 线性相关性线性相关衡量变量或数据集特征之间的数学关系与一个线性函数的接近程度。如果两个特征之间的关系更接近于某个线性函数,那么它们的线性相关性就更强,相关系数的绝对值就更高。 皮尔逊相关系数考虑一个有两个特征的数据集:和。每个特征有个值,所以和是个元组。的第一个值对应的第一个值,的第二个值对应的第二个值,以此类推。那么,就有对对应的数值:,,以此类推。这些对中的每一个都代表一个单一的观察。 皮尔逊相关系数是对两个特征之间的线性关系的衡量。它是 和 的协方差与它们的标准差的乘积的比率。它通常用字母 表示,并称为皮尔逊的 。我们可以用这个方程式来表示这个值的数学性质。 这里, 的值为 。 和 的平均值用mean(x)和mean(y)来表示。这个公式表明,如果较大的 值倾向于对应较大的 值,反之亦然,则 为正。另一方面,如果较大的 值大多与较小的 值相关,反之亦然,则 为负。 以下是关于皮尔逊相关系数的一些重要事实: 皮尔逊相关系数可以在 的范围内取任何实值。 最大值 对应于 和 之间存在完美的正线性关系的情况。换句话说,较大的 值对应较大的 值,反之亦然。 的值表示 和 之间的正相关。 的值对应于 和 之间没有线性关系的情况。 的值表示 和 之间的负相关。 最小值 对应于 和 之间存在完美的负线性关系的情况。换句话说,较大的 值对应较小的 值,反之亦然。 上述事实可归纳为以下表格。 皮尔逊的r值x与y之间的相关性等于1完美正线性关系大于0正相关关系等于0没有线性关系小于0负相关关系等于-1完美的负线性关系简而言之, 的绝对值越大,表明相关性越强,越接近于线性函数。 的绝对值越小,表示相关性越弱。 SciPy实现线性回归线性回归是寻找尽可能接近特征间实际关系的线性函数的过程。换句话说,我们确定最能描述特征之间关联的线性函数。这个线性函数也被称为回归线。 我们可以用 SciPy 实现线性回归。我们会得到最接近两个数组之间关系的线性函数,以及皮尔逊相关系数。要想开始,我们首先需要导入库,并准备一些数据来进行处理。 import numpy as np import scipy.stats x = np.arange(10, 20) y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48])在这里,我们导入numpy和scipy.stats并定义变量x和y。 我们可以使用 scipy.stats.linregress()[8] 来对两个相同长度的数组进行线性回归。提供数组作为参数,并通过使用点符号获得输出。 >>> result = scipy.stats.linregress(x, y) >>> result.slope 7.4363636363636365 >>> result.intercept -85.92727272727274 >>> result.rvalue 0.7586402890911869 >>> result.pvalue 0.010964341301680825 >>> result.stderr 2.257878767543913就这样我们已经完成了线性回归,并得到了以下结果。我们已经完成了线性回归并得到了以下结果。 .slope: 回归线的斜率 .intercept: 回归线的截距 .pvalue: p值 .stderr: 估计梯度的标准误差 我们将在后面学习如何将这些结果可视化。 也可以给linregress()提供一个参数,但它必须是一个二维数组,其中一维的长度为2。 xy = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19], [2, 1, 4, 5, 8, 12, 18, 25, 96, 48]]) scipy.stats.linregress(xy) LinregressResult(slope=7.4363636363636365, intercept=-85.92727272727274, rvalue=0.7586402890911869, pvalue=0.010964341301680825, stderr=2.257878767543913)linregress() 将 的第一行作为一个特征,将第二行作为另一个特征,结果与前面的例子完全一样,因为 包含的数据与 和 加起来的数据相同。 注意: 上面例子中,scipy.stats.linregress()认为行是特征,列是观测值。 机器学习 的通常做法是相反的:行是观察值,列是特征。许多机器学习库,如Pandas、Scikit-Learn、Keras等都遵循这一惯例。 每当在分析数据集中的相关性时,我们应该注意观察和特征的表示方式。 如果我们提供 的转置,或者一个10行2列的NumPy数组,linregress()将返回同样的结果。在NumPy中,我们可以通过多种方式对矩阵进行转置。 transpose() .transpose() .T xy.T array([[10, 2], [11, 1], [12, 4], [13, 5], [14, 8], [15, 12], [16, 18], [17, 25], [18, 96], [19, 48]])现在我们知道如何获得转置,可以把一个转置传给linregress()。第一列将是一个特征,第二列是另一个特征。 scipy.stats.linregress(xy.T) LinregressResult(slope=7.4363636363636365, intercept=-85.92727272727274, rvalue=0.7586402890911869, pvalue=0.010964341301680825, stderr=2.257878767543913)用.T来获取 的转置。linregress()对 及其转置的工作方式相同。它通过沿长度为2的维度分割数组来提取特征。 还应该注意到数据集是否包含缺失值。在数据科学和机器学习中,我们会经常发现一些缺失或异常的数据。在Python、NumPy、SciPy和Pandas中,通常的表示方法是使用 NaN 或 Not a Number 值。但是如果数据中含有nan值,那么用 linregress() 就会得到一个无用的结果。 >>> scipy.stats.linregress(np.arange(3), np.array([2, np.nan, 5])) LinregressResult(slope=nan, intercept=nan, rvalue=nan, pvalue=nan, stderr=nan)在这种情况下,我们的结果对象返回所有的 nan 值。在Python中,nan 是一个特殊的浮点值,我们可以通过使用以下任何一种方法得到。 float('nan') math.nan numpy.nan 我们也可以用math.isan()[9]或numpy.isan()[10]检查一个变量是否对应于nan。 NumPy和SciPy计算皮尔逊相关系数我们已经看到了如何用corrcoef()和pearsonr()获得皮尔逊相关系数。 >>> r, p = scipy.stats.pearsonr(x, y) >>> r 0.7586402890911869 >>> p 0.010964341301680829 >>> np.corrcoef(x, y) array([[1. , 0.75864029], [0.75864029, 1. ]])注意如果向 pearsonr() 提供一个带有nan值的数组,会抛出一个ValueError异常。 有几个额外的细节值得考虑。首先,np.corrcoef()可以接受两个NumPy数组作为参数。相反,可以传递一个单一的二维数组,其值与参数相同。 np.corrcoef(xy) array([[1. , 0.75864029], [0.75864029, 1. ]])在这个例子和以前的例子中,结果是一样的。同样,第一行 代表一个特征,而第二行代表另一个特征。 如果想得到三个特征的相关系数,那么我们只要提供一个有三行的数字二维数组作为参数。 xyz = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19], [2, 1, 4, 5, 8, 12, 18, 25, 96, 48], [5, 3, 2, 1, 0, -2, -8, -11, -15, -16]]) np.corrcoef(xyz) array([[ 1. , 0.75864029, -0.96807242], [ 0.75864029, 1. , -0.83407922], [-0.96807242, -0.83407922, 1. ]])我们将再次获得相关矩阵,但这个矩阵将比以前的大。 x y z x 1.00 0.76 -0.97 y 0.76 1.00 -0.83 z -0.97 -0.83 1.00这是因为corrcoef()将 的每一行视为一个特征。值0.76是 的前两个特征的相关系数。这与前面例子中 和 的系数相同。-0.97代表第一个和第三个特征的Pearson's r,而-0.83是最后两个特征的Pearson's r。 把 nan 数据传给corrcoef()时: arr_with_nan = np.array([[0, 1, 2, 3], [2, 4, 1, 8], [2, 5, np.nan, 2]]) np.corrcoef(arr_with_nan) array([[1. , 0.62554324, nan], [0.62554324, 1. , nan], [ nan, nan, nan]])在这个例子中,arr_with_nan的前两行(或特征)没有问题,但第三行[2, 5, np.nan, 2]包含一个nan值。所有不包括nan的特征的计算都很好。而依赖于最后一行的计算结果是nan。 默认情况下,numpy.corrcoef()认为行是特征,列是观测值。如果想要得到与在机器学习中的惯例计算时,那么需要使用参数rowvar=False。 xyz.T array([[ 10, 2, 5], [ 11, 1, 3], [ 12, 4, 2], [ 13, 5, 1], [ 14, 8, 0], [ 15, 12, -2], [ 16, 18, -8], [ 17, 25, -11], [ 18, 96, -15], [ 19, 48, -16]]) np.corrcoef(xyz.T, rowvar=False) array([[ 1. , 0.75864029, -0.96807242], [ 0.75864029, 1. , -0.83407922], [-0.96807242, -0.83407922, 1. ]])这个数组与我们之前看到的数组相同。虽然这里惯例不同,但结果是一样的。 Pandas计算皮尔逊相关系数前面我们已经使用 Series 和 DataFrame 对象的方法来计算相关系数。 import pandas as pd x = pd.Series(range(10, 20)) y = pd.Series([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) z = pd.Series([5, 3, 2, 1, 0, -2, -8, -11, -15, -16]) xy = pd.DataFrame({'x-values': x, 'y-values': y}) xyz = pd.DataFrame({'x-values': x, 'y-values': y, 'z-values': z}) xyz x-values y-values z-values 0 10 2 5 1 11 1 3 2 12 4 2 3 13 5 1 4 14 8 0 5 15 12 -2 6 16 18 -8 7 17 25 -11 8 18 96 -15 9 19 48 -16现在有三个名为x、y和z的系列对象,也有两个DataFrame对象,xy和xyz。 注意:当使用DataFrame实例时,行是观察值,列是特征。 前面已经介绍了如何对Series对象使用.corr()来获得皮尔逊相关系数。 x.corr(y) 0.7586402890911867在这里,在一个对象上调用.corr(),并将另一个对象作为第一个参数传递。 如果提供了一个nan值,那么.corr()将排除包含nan值的观察值。 >>> u, u_with_nan = pd.Series([1, 2, 3]), pd.Series([1, 2, np.nan, 3]) >>> v, w = pd.Series([1, 4, 8]), pd.Series([1, 4, 154, 8]) >>> u.corr(v) 0.9966158955401239 >>> u_with_nan.corr(w) 0.9966158955401239在这两个例子中,得到的相关系数的值是一样的。这是因为.corr()忽略了有缺失值的一对数值(np.nan, 154)。 也可以对 DataFrame 对象使用.corr(),可以用它来获得其列的相关矩阵。 corr_matrix = xy.corr() corr_matrix x-values y-values x-values 1.00000 0.75864 y-values 0.75864 1.00000得到的相关矩阵是一个新的 DataFrame 实例,并包含xy['x-values']和xy['y-values']列的相关系数。这种有标签的结果通常在工作中非常方便,因为可以用它们的标签或整数位置索引来访问它们。 >>> corr_matrix.at['x-values', 'y-values'] 0.7586402890911869 >>> corr_matrix.iat[0, 1] 0.7586402890911869这个例子显示了两种访问数值的方式。 使用.loc通过行和列标签访问一个单一的值。 使用.iloc来通过其行和列的位置索引访问一个值。 可以用同样的方式对包含三列或更多列的DataFrame对象应用.corr()。 xyz.corr() x-values y-values z-values x-values 1.000000 0.758640 -0.968072 y-values 0.758640 1.000000 -0.834079 z-values -0.968072 -0.834079 1.000000我们会得到一个相关矩阵,其相关系数如下。 x-values 和 y-values 为 0.758640 x-values 和 z-values 为 -0.968072 y-values 和 z-values 为 -0.834079 另一个有用的方法是.corrwith()[11],它计算一个DataFrame对象的行或列与作为第一个参数传递的另一个系列或DataFrame对象之间的相关系数。 xy.corrwith(z) x-values -0.968072 y-values -0.834079 dtype: float64在这种情况下,结果是一个新的Series对象,其中包括列xy['x-values']和z值的相关系数,以及xy['y-values']和z的系数。 .corrwith()有一个可选的参数axis,用于指定是列还是行代表特征。axis的默认值是0,而且它也默认为列代表特征。还有一个drop参数,它表示如何处理缺失的值。 .corr()和.corrwith()都有可选的参数方法来指定我们要计算的相关系数。皮尔逊相关系数是默认返回的,所以在这种情况下我们不需要提供它。 相关性等级相关性等级比较了与两个变量或数据集特征相关的数据的等级或排序。如果排序相似,那么就是强相关、正相关、高相关。然而,如果排序接近反向,那么就是强相关、负相关、低相关。换句话说,等级相关只关注数值的顺序,而不关注数据集的特定数值。 为了说明线性相关和等级相关的区别,请看下图。 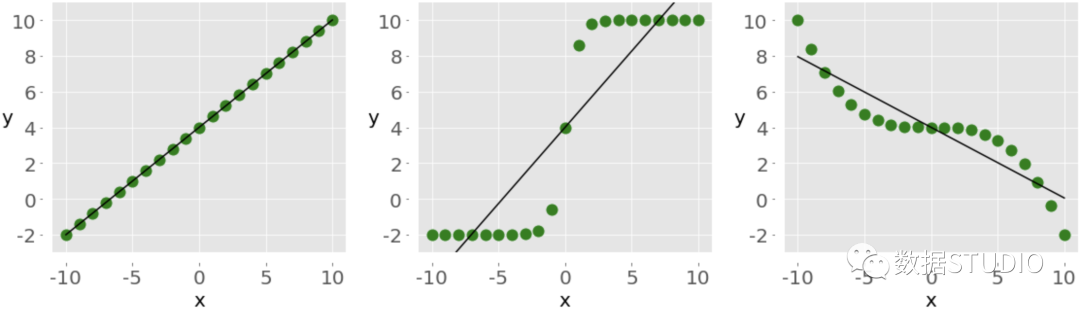
左边的图在 和 之间有一个完美的正线性关系,所以 。中间的图显示正相关,右边的图显示负相关。然而,它们都不是线性函数,所以 与 或 不同。 当只看排序或等级时,这三种关系都是完美的!左边和中间的图显示了较大的 值总是对应较大的 值的观察结果。这就是完美的正相关关系。右边的图显示了相反的情况,即完美的负相关关系。 Spearman相关系数两个特征之间的Spearman相关系数是它们的等级值之间的Pearson相关系数。它的计算方法与Pearson相关系数相同,但考虑到了它们的rank而不是它们的数值。它通常用希腊字母rho(ρ)表示,称为Spearman's rho。 假设有两个n元组, 和 ,其中 , 是作为对应值的观察值对。我们可以用与Pearson系数相同的方法来计算Spearman相关系数 ρ。使用rank而不是 和 的实际值。 以下是关于Spearman相关系数的一些重要事实。 它可以在 ρ 的范围内取一个实数。 它的最大值 ρ 对应于 和 之间存在单调增长函数的情况。换句话说,更大的 值对应更大的 值,反之亦然。 它的最小值 ρ 对应于 和 之间存在单调递减函数的情况。换句话说,较大的x值对应较小的 值,反之亦然。 我们可以在Python中计算Spearman's rho,方法与计算Pearson's r非常相似。 Kendall相关系数再次开始考虑两个n元组,和。每一个对是一个单一的观察。一对观察值和,其中<,将是三种情况之一。 如果 或 是一致的。 如果 或 不协调 如果在中出现平局或在中出现平局,都不会出现。 Kendall相关系数比较了数据的一致和不一致对的数量。这个系数是基于协和对和不协和对的数量相对于 对数量的差异。它通常用希腊字母 τ 表示,并称为Kendall's tau。 根据scipy.stats的官方文档[12],Kendall相关系数的计算方法是 τ⁺⁺ˣ⁺ʸ,其中。 ⁺ 是协和对的数量 是不和谐对的数量 ˣ 是仅在x中存在的平局数 ʸ 是仅在y中的平局数 如果在 和 中都出现了平局,那么它就不包括在 ˣ 或 ʸ 中。 维基百科关于Kendall相关系数的页面给出了以下表达式: τᵢⱼᵢⱼ 符号函数 在 时为 , 时为 , 时为 。 关于Kendall相关系数的一些重要事实如下。 它可以在 τ 的范围内取一个实值。 它的最大值 τ 对应于x和y中的相应数值的rank相同的情况。换句话说,所有的配对都是一致的。 它的最小值 τ,对应于x中的rank与y中的rank相反的情况,换句话说,所有配对都是不和谐的。 我们可以在Python中计算Kendall's tau,就像我们计算Pearson's r一样。 SciPy 实现 Rank我们可以使用scipy.stats来确定一个数组中每个值的rank。首先导入库并创建NumPy数组。 import numpy as np import scipy.stats x = np.arange(10, 20) y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) z = np.array([5, 3, 2, 1, 0, -2, -8, -11, -15, -16])数据已经准备好了,可以用scipy.stats.rankdata()[13]确定NumPy数组中每个值的rank。 >>> scipy.stats.rankdata(x) array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]) >>> scipy.stats.rankdata(y) array([ 2., 1., 3., 4., 5., 6., 7., 8., 10., 9.]) >>> scipy.stats.rankdata(z) array([10., 9., 8., 7., 6., 5., 4., 3., 2., 1.])数组 和 是单调的,所以它们的rank也是单调的。 中最小的值是1,它对应的rank是1。第二个最小的值是2,它对应于rank2。最大的值是96,它对应于最大的rank10,因为数组里有10个项目。 rankdata()有一个可选的参数方法。它告诉Python在数组中有并列的情况下该怎么做 (如果两个或多个值相等)。默认情况下,它为它们分配rank的平均值。 scipy.stats.rankdata([8, 2, 0, 2]) array([4. , 2.5, 1. , 2.5])有两个值为2的元素,它们的rank为2.0和3.0。值为0的rank为1.0,值为8的rank为4.0。那么,两个值为2的元素将得到相同的rank2.5。 rankdata()将nan值视为大值。 >>> scipy.stats.rankdata([8, np.nan, 0, 2]) array([3., 4., 1., 2.])在这种情况下,np.nan的值对应于最大的rank4.0。也可以用np.argsort()[14]获得rank。 np.argsort(y) + 1 array([ 2, 1, 3, 4, 5, 6, 7, 8, 10, 9])argsort()返回数组项在排序后的数组中的索引。这些索引是基于零的,所以需要在所有的索引上加1。 NumPy和SciPy实现Rank相关性可以用scipy.stats.spearmanr()计算 Spearman 相关系数。 >>> result = scipy.stats.spearmanr(x, y) >>> result SpearmanrResult(correlation=0.9757575757575757, pvalue=1.4675461874042197e-06) >>> result.correlation 0.9757575757575757 >>> result.pvalue 1.4675461874042197e-06 >>> rho, p = scipy.stats.spearmanr(x, y) >>> rho 0.9757575757575757 >>> p 1.4675461874042197e-06spearmanr()返回一个包含Spearman相关系数和p值的对象。可以通过两种方式访问特定的值。 使用点符号(result.correlation和result.pvalue)。 使用Python解包(rho, p = scipy.stats.spearmanr(x, y))。 如果向spearmanr()提供包含x和y相同数据的二维数组xy,我们可以得到同样的结果。 >>> xy = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19], ... [2, 1, 4, 5, 8, 12, 18, 25, 96, 48]]) >>> rho, p = scipy.stats.spearmanr(xy, axis=1) >>> rho 0.9757575757575757 >>> p 1.4675461874042197e-06的第一行是一个特征,而第二行是另一个特征。我们可以修改这一点。可选的参数axis决定了是列(axis=0)还是行(axis=1)代表特征。默认行为是行是观测值,列是特征。 另一个可选的参数nan_policy定义了如何处理nan值。它可以取三个值中的一个。 如果输入中存在一个nan值,'propagate' 返回nan。这是默认的行为。 'raise' 如果在输入中存在一个nan值,会引发ValueError。 'omit' 忽略有nan值的观测值。 如果提供一个有两个以上特征的二维数组,那么将得到相关矩阵和p值矩阵。 >>> xyz = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19], ... [2, 1, 4, 5, 8, 12, 18, 25, 96, 48], ... [5, 3, 2, 1, 0, -2, -8, -11, -15, -16]]) >>> corr_matrix, p_matrix = scipy.stats.spearmanr(xyz, axis=1) >>> corr_matrix array([[ 1. , 0.97575758, -1. ], [ 0.97575758, 1. , -0.97575758], [-1. , -0.97575758, 1. ]]) >>> p_matrix array([[6.64689742e-64, 1.46754619e-06, 6.64689742e-64], [1.46754619e-06, 6.64689742e-64, 1.46754619e-06], [6.64689742e-64, 1.46754619e-06, 6.64689742e-64]])相关矩阵中的数值-1表明,第一和第三特征具有完美的负等级相关性,即第一行中较大的数值总是对应于第三行中较小的数值。 我们可以用kendalltau()获得Kendall相关系数。 >>> result = scipy.stats.kendalltau(x, y) >>> result KendalltauResult(correlation=0.911111111111111, pvalue=2.9761904761904762e-05) >>> result.correlation 0.911111111111111 >>> result.pvalue 2.9761904761904762e-05 >>> tau, p = scipy.stats.kendalltau(x, y) >>> tau 0.911111111111111 >>> p 2.9761904761904762e-05kendalltau()的工作原理与spearmanr()很相似。它接收两个一维数组,有可选参数nan_policy,并返回一个包含相关系数和p值的对象。 然而,如果只提供一个二维数组作为参数,那么kendalltau()将引发一个TypeError。如果传入两个相同形状的多维数组,那么它们将在计算前被压扁。 Pandas实现Rank相关性可以用Pandas计算Spearman和Kendall相关系数。导入pandas并创建一些Series和DataFrame实例。 >>> import pandas as pd >>> x, y, z = pd.Series(x), pd.Series(y), pd.Series(z) >>> xy = pd.DataFrame({'x-values': x, 'y-values': y}) >>> xyz = pd.DataFrame({'x-values': x, 'y-values': y, 'z-values': z})现在有了这些Pandas对象,可以使用.corr()和.corrwith(),就像计算皮尔逊相关系数时那样。只需要用可选的参数方法指定所需的相关系数,默认为'pearson'。 要计算Spearman's rho可通过设置参数method=spearman。 >>> x.corr(y, method='spearman') 0.9757575757575757 >>> xy.corr(method='spearman') x-values y-values x-values 1.000000 0.975758 y-values 0.975758 1.000000 >>> xyz.corr(method='spearman') x-values y-values z-values x-values 1.000000 0.975758 -1.000000 y-values 0.975758 1.000000 -0.975758 z-values -1.000000 -0.975758 1.000000 >>> xy.corrwith(z, method='spearman') x-values -1.000000 y-values -0.975758 dtype: float64如果想要得到 Kendall's tau,那么设置参数method=kendall。 >>> x.corr(y, method='kendall') 0.911111111111111 >>> xy.corr(method='kendall') x-values y-values x-values 1.000000 0.911111 y-values 0.911111 1.000000 >>> xyz.corr(method='kendall') x-values y-values z-values x-values 1.000000 0.911111 -1.000000 y-values 0.911111 1.000000 -0.911111 z-values -1.000000 -0.911111 1.000000 >>> xy.corrwith(z, method='kendall') x-values -1.000000 y-values -0.911111 dtype: float64正如我们所看到的,与SciPy不同,我们可以使用单一的二维数据结构(数据帧)。 相关性的可视化数据可视化在统计学和数据科学中非常重要。它可以帮助我们更好地理解数据,更好地了解特征之间的关系。在本节中,我们将学习如何用X-Y图直观地表示两个特征之间的关系。还将使用热图来可视化一个相关的矩阵。 我们将学习如何准备数据和获得某些相关图表。要开始使用,首先导入matplotlib.pyplot。 import matplotlib.pyplot as plt plt.style.use('ggplot')在这里,我们使用plt.style.use('ggplot')来设置图的样式。如果我们想的话,可以随意跳过这一行。 我们将使用前几节中的数组x、y、z和xyz。我们可以再次创建它们,以减少滚动的次数。 >>> import numpy as np >>> import scipy.stats >>> x = np.arange(10, 20) >>> y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> z = np.array([5, 3, 2, 1, 0, -2, -8, -11, -15, -16]) >>> xyz = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19], ... [2, 1, 4, 5, 8, 12, 18, 25, 96, 48], ... [5, 3, 2, 1, 0, -2, -8, -11, -15, -16]]) 带有回归线的X-Y图首先用回归线、回归方程和皮尔逊相关系数创建一个x-y图。可以用linregress()得到回归线的斜率、截距以及相关系数。 slope, intercept, r, p, stderr = scipy.stats.linregress(x, y)现在有了需要的所有数值,我们也可以得到带有回归线方程和相关系数值的字符串。f-strings在这方面非常方便。 >>> line = f'Regression line: y={intercept:.2f}+{slope:.2f}x, r={r:.2f}' >>> line 'Regression line: y=-85.93+7.44x, r=0.76'现在,用.plot()创建x-y图。 fig, ax = plt.subplots() ax.plot(x, y, linewidth=0, marker='s', label='Data points') ax.plot(x, intercept + slope * x, label=line) ax.set_xlabel('x') ax.set_ylabel('y') ax.legend(facecolor='white') plt.show()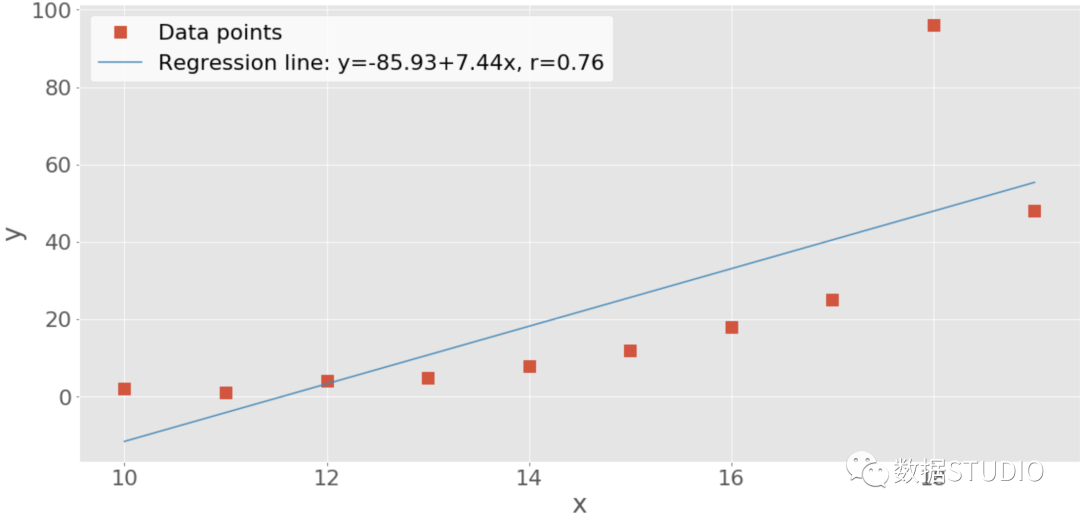
红色方块代表观测值,而蓝色线是回归线。图例中列出了它的方程,以及相关系数。 相关矩阵的热图当我们有很多特征时,相关矩阵可能会变得非常大。我们可以将其直观地呈现为热图,每个字段都有与之对应的颜色。可以把它以热图的形式直观地展示出来,每个字段都有与它的值相对应的颜色。 corr_matrix = np.corrcoef(xyz).round(decimals=2) corr_matrix array([[ 1. , 0.76, -0.97], [ 0.76, 1. , -0.83], [-0.97, -0.83, 1. ]])用 .round() 对相关矩阵中的数字进行四舍五入可能会很方便,因为它们将被显示在热图上。 最后,用.imshow() 创建我们的热图,并将相关矩阵作为其参数。 fig, ax = plt.subplots() im = ax.imshow(corr_matrix) im.set_clim(-1, 1) ax.grid(False) ax.xaxis.set(ticks=(0, 1, 2), ticklabels=('x', 'y', 'z')) ax.yaxis.set(ticks=(0, 1, 2), ticklabels=('x', 'y', 'z')) ax.set_ylim(2.5, -0.5) for i in range(3): for j in range(3): ax.text(j, i, corr_matrix[i, j], ha='center', va='center', color='r') cbar = ax.figure.colorbar(im, ax=ax, format='% .2f') plt.show()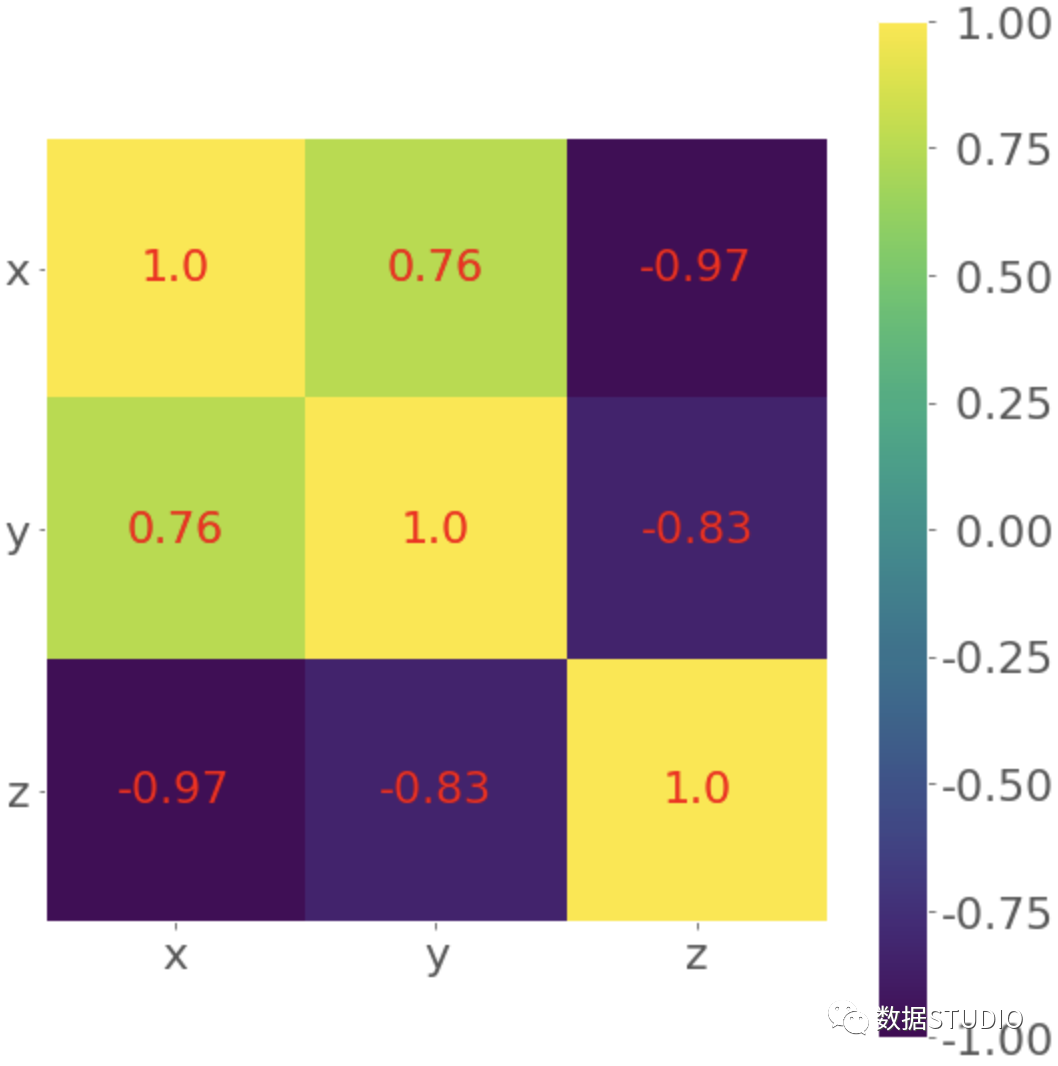
结果是一个带有系数的表格,这些颜色可以帮助我们解释输出。在这个例子中,黄色代表数字1,绿色对应于0.76,紫色用来表示负数。 总结我们现在知道了,相关系数是衡量数据集的变量或特征之间的关联的统计数据。它们在数据科学和机器学习中非常重要。 现在我们可以用Python来计算了。 Pearson’s 积点相关系数 Spearman’s 等级相关系数 Kendall's 等级相关系数 现在我们可以使用NumPy、SciPy和Pandas的相关函数和方法来有效地计算这些(和其他)统计数据,即使是在我们处理大型数据集的时候。我们还知道如何用Matplotlib图和热图来可视化数据、回归线和相关矩阵。 参考资料[1] 线性相关: https://www.statlect.com/fundamentals-of-probability/linear-correlation [2]等级: https://en.wikipedia.org/wiki/Rank_correlation [3]统计函数: https://docs.scipy.org/doc/numpy/reference/routines.statistics.html [4]np.corrcoef(): https://docs.scipy.org/doc/numpy/reference/generated/numpy.corrcoef.html [5]scipy.stats: https://docs.scipy.org/doc/scipy/reference/stats.html [6].corr(): https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.corr.html [7].__call__(): https://docs.python.org/3/reference/datamodel.html#emulating-callable-objects [8]scipy.stats.linregress(): https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.linregress.html [9]math.isan(): https://docs.python.org/3.7/library/math.html#math.isnan [10]numpy.isan(): https://docs.scipy.org/doc/numpy/reference/generated/numpy.isnan.html [11].corrwith(): https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.corrwith.html [12]scipy.stats的官方文档: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kendalltau.html [13]scipy.stats.rankdata(): https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.rankdata.html [14]np.argsort(): https://docs.scipy.org/doc/numpy/reference/generated/numpy.argsort.html -------- End -------- 推荐👇同名微信视频号 图解Pandas图文00-内容框架介绍 | 图文01-数据结构介绍 | 图文02-创建数据对象 | 图文03-操作Excel文件 | 图文04-常见的数据访问 | 图文05-常见的数据运算 | 图文06-常见的数学计算 | 图文07-常见的数据统计 | 图文08-常见的数据筛选 | 图文09-常见的缺失值处理 | 图文10-数据合并操作 | 图文11-Groupby分组操作 |
【本文地址】
今日新闻 |
推荐新闻 |